プロテオミクス Proteomics
![]()
18 September 2016 版を翻訳一部改変
| このページの内容 |
いくつかの定義付け
ゲノム Genome
生物における完全な遺伝子のセット(半数体のセット)。[ゲノムサイズについてはこちら]
その DNA に対する修復不可能な損傷(すなわち突然変異)がない限り,ゲノムは不変である。
トランスクリプトーム Transcriptome
最も一般的な定義:ゲノムから 転写 されたすべてのメッセンジャー RNA ( mRNA ) 分子 。
厳密に言えば,ゲノムの DNA から転写された RNA 分子すべてと定義されるだろう。これにはいろいろな種類の非翻訳,タンパク質をコードしないRNAも含まれる。
DNA のおよそ75%が RNA に転写されるものと考えられている。ただし,このうちの1.5%がタンパク質の合成に利用される mRNA である。
プロテオーム Proteome
2 つの一般的な定義付けは以下の通りである:
- 細胞によって合成されるタンパク質のすべて ( 本来の定義 )
- 特定の時期に,特定の細胞で合成されるタンパク質のすべて ( このページではこの定義を採用している )
メタボローム Metabolome
代謝の過程に必要なすべて,たとえば,
- 酵素
- 補酵素
- 小分子の代謝産物, たとえば,
- プレ・メッセンジャー RNA (pre-mRNA)の 選択的スプライシング が起こる。
- プレ・メッセンジャー RNA (pre-mRNA)の RNA 編集(RNA editing)
- 炭水化物残基が付加されて, 糖タンパク質 が形成される。
- タンパク質のあるアミノ酸にリン酸基が付加される。
- 等々
- 1 つの分化した細胞から他の細胞種(たとえば,赤血球とリンパ球 )が形成されることもあり,また
- 刻一刻と,細胞の活動が変化することによって,たとえば,
- ゲノムの複製 の準備や,
- ゲノム DNA の損傷を修復 したり,
- 新たに利用できる栄養素や サイトカイン に反応したり,
- ホルモンの刺激に反応したり,[ホルモン作用の例はこちら]
- 等々,の細胞活動に依存してタンパク質構成も変化するのである。
- 均質な細胞集団を分離する(たとえば,エネルギー源としてグルコースからガラクトースへちょうど切り替えた酵母などのように)。
- 細胞成分を抽出し,タンパク質混合液と他の成分を分離する。
- 二次元電気泳動法 によってタンパク質混合液のタンパク質を分離する。この方法により,x 方向とy 方向に順次泳動すれば(したがって二次元),かなり複雑な組成の試料も分析可能である。タンパク質は,
- まず,それらの電荷によって泳動し (一次元),
- 次いで,それらの分子量によって二次元に展開する。
- ゲルを染色すると種々のタンパク質のスポットが検索できる。
ラット肝細胞のタンパク質の二次電気泳動像 - スポットを打ち抜く。
- タンパク質分解酵素 (たとえば,トリプシン)を添加し,そのスポットを ペプチド 混合液に分解する。
- その混合液を 質量分析計 で分析する。これにより,ペプチドがはっきりとしたペプチド分画に分離される。
- 得られた結果を,(同じ酵素で消化された)既知のタンパク質のデータベースで照合する。
- 各ペプチドを分離して,もう一度質量分析計で以下のように条件を修正して分析する:
- まず任意にペプチドを小数のアミノ酸断片を含むように分解して,
- 次に,各断片をの質量を分析する。
- 得られた結果を既知のアミノ酸配列を含むデータベースと照合する。
- 重なり合う部分を利用しながら,ペプチド全体の配列がわかるように組み立てる。
- アミノ酸配列から DNA の塩基配列を逆翻訳して決定していく。
- その塩基配列を含む オープン・リーディング・フレーム(ORF)をゲノム・データベースから検索する。
- そのオープン・リーディング・フレームを翻訳し,そのタンパク質のアミノ酸配列を得る。
- 固定相(担体)にリガンドを結合させたカラムを作る。
- カラムに ”目的タンパク質”が含まれるタンパク混合溶液を流す。
- リガンドと結合する”目的タンパク質”だけがカラム内に留まり,その他のものは流出する。
- タンパク質同士の結合力を弱める緩衝液をカラムに流す。
- 結合していた”目的タンパク質”が分離する。
- 出芽酵母は,外来 DNA を導入した プラスミド で形質転換されやすい ( すなわち,組み換え DNA 技術である ) 。
- 出芽酵母は半数体または倍数体のどちらでも生存できる。
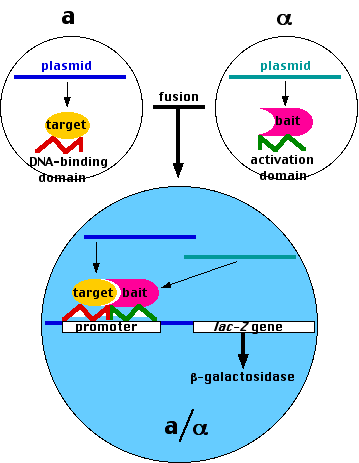
- 半数体細胞は,それらがお互いの交配型であれば融合して倍数体細胞を形成する ( 右図では a と α で表わしている )。
- DNA-結合領域 DNA-binding domain : 遺伝子のスイッチを入れる特異的な プロモーター に結合できるDNA 配列領域。
- 活性化領域 activation domain : RNAポリメラーゼII複合体を誘導し下流の遺伝子の転写を活性化するのに必要な領域。
- 組み換え DNA?技術を用い,以下を含むプラスミドを作製する:
- lacZ 遺伝子(酵素 β-ガラクトシダーゼをコードする)のような “リポーター遺伝子” の発現に必要な転写調節因子の DNA-結合領域をコードする DNA
- 検索したい協同タンパク質の “標的” タンパク質をコードする DNA
- 同じ手法を用いて,以下を含むいろいろなプラスミドを作製する:
- 転写調節因子の 活性化領域 をコードする DNA
- 共同して働いているパートナータンパク質 ( 右図では “bait(おとり)” タンパク質 ) をコードする DNA
(自動化されたシステムで,酵母の全ゲノム約6,000個の遺伝子に対応するプラスミドライブラリーを構築する。) - それぞれのプラスミドを α酵母細胞に導入し,それぞれのクローンを培養する。
- 各αクローンと “標的” クローン ( a ) を相互作用させる。
- “bait” 遺伝子をもつプラスミドの転写と翻訳によって生産された融合タンパク質が “標的” を含む融合タンパク質に結合すると,
- 転写調節因子の2つの領域が相互作用してリポーター遺伝子 ( この場合 lacZ ) の発現を促す。
- ( リポーター遺伝子の発現によって ) 酵素 β-ガラクトシダーゼの基質を含む培地で発育させると,リポーター遺伝子を発現したコロニーの部分が青色に変わる。
- これらのコロニーの DNA を分離して,塩基配列を決定する。
- その結果: “標的” タンパク質と共同して働くタンパク質が同定できる。
- 大腸菌に感染する DNA バクテリオファージ
- その外殻タンパク質の 1 つが外来タンパク質断片を含んでいても失われない感染力
- バクテリオファージを,以下のように形質転換する:
- 対象生物から採取した任意の DNA ライブラリー
- ウイルス外殻タンパク質の 1 つをコードしている DNA
- 大腸菌にこれらのファージを感染させる。
- ウイルスが複製される時,組み換え遺伝子を伝達するだけでなく,外殻タンパク質としてそれを発現する。
- どちらも新しい ビリオン 《細胞外で感染性を有するウイルス粒子》に取り込まれる。
- 混在するウイルスを採取する。
- アフィニティー・クロマトグラフィにより,”標的” タンパク質の結合するものを探索する。
- “標的” タンパク質に結合できる外来タンパク質 ( ペプチド ) を発現しているウイルスが固定相と親和力により結合する。
- 結合したファージを緩衝液で洗い出す。
- 上記ステップ 6 ~ 8 を反復して,いろいろなファージを選別しておく。
- 大腸菌に感染させる。
- 個々のコロニー ( クローン ) として増殖させる。
- 外殻タンパク質遺伝子の塩基配列を決定し,そこに挿入された外来 DNA の塩基配列を検索する。
- コドン表を用いて,ペプチドのアミノ酸配列を決定する。
- この配列をもつタンパク質をデータベースで検索する。
- その結果: “標的” タンパク質に結合する別のタンパク質が決定される。
- 対象生物から得られた数百,あるいは数千もの異なるタンパク質がライブラリーとして,チップのスポットに追加できる。
- そのように作製したチップに,共同して働くと予測されるタンパク質を含む混合液を添加する。
- チップ上のいずれかのタンパク質が,混合液中のタンパク質と相互作用を示す。
- 蛍光標識色素を添加すると,それらを同定できる。
- 化学的に非常に多様性を示す ( たとえば,疎水性と親水性など ) 。
- 数種類の非共有相互作用によってお互いに結合する。
- X 線結晶学 X-ray crystallography
- 核磁気共鳴 nuclear magnetic resonance ( NMR ) 分光法
その時点で細胞に存在する分子
細胞の分化の状態やその時の活動状況によって変動する。
プロテオーム Proteome
プロテオームは ” prote ( タンパク質 ) + genome ” が語源で,ゲノムの各遺伝子に対応する全てのタンパク質を指している。 以下の機構によって, 1 つの遺伝子から,多種類のタンパク質が生じる場合があるので,単なるゲノムに比べるとかなり複雑である。
ヒトはおよそ2万1000個の遺伝子を持つが,我々はおそらく少なくとも10倍の各種タンパク質を造ることができる。我々の遺伝子の大部分は,選択的スプライシング が起こる pre-mRNA を生産する。
タンパク質はすべての生物の構造と機能の両方に関わるので,プロテオミクス研究は重要である。遺伝子は単にタンパク質を作製する設計図であり,生命を形成しているのはタンパク質である。
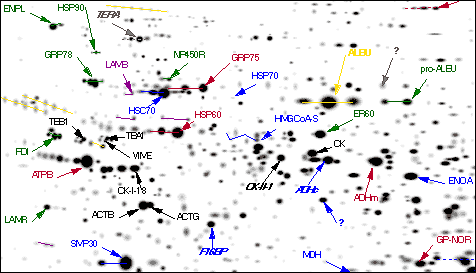
ヒト細胞はいつでも,約10,000種類のタンパク質を含有するだろう。すなわち,あるものは多量に(例えばリボソーム・タンパク質など),またあるものは低濃度で(例えば転写因子など)。
細胞の中にあるタンパク質は多種多様である:
どのように研究されているのか
{kind=link}
もし一致するものがなかった場合,未知のタンパク質を見出した可能性がある。
新しいタンパク質の機能を探る
あるタンパク質は単独で作用し,それらの多くの機能は明らかにされてきている。しかし,細胞内の大部分のタンパク質はお互いに関連しながら作用している。
例:
協同的に機能するタンパク質を見つける方法
1. アフィニティー・クロマトグラフィー
クロマトグラフィーとは, 固定相(または担体)と呼ばれる物質の表面あるいは内部を,移動相と呼ばれる溶媒が通り抜ける過程で生じる相互作用を利用して,異なる性質の溶質を分離する方法である。
アフィニティー・クロマトグラフィーとは,結合親和性でタンパク質を分けるクロマトグラフィーを指す。酵素,受容体,抗体などのタンパク質は特定の物質(リガンド)に強い結合親和性をもつ。
具体的な手法:
2. 酵母ツーハイブリッドシステム
出芽酵母(Saccharomyces cerevisiae)は, ( 協同的に働く ) パートナー・タンパク質を検索する優れたツールとして利用できる。
転写調節因子 ( タンパク質 )に,以下のものが含まれるので,ハイブリッドシステムに都合がよい:
その方法
このハイブリット法を用いると,酵素や他の生物におけるタンパク質と相互作用する多くのタンパク質を同定することが可能となる。
(Cellの2005年9月23日号では,ヒトタンパク質が共同して働くペアの内3,000を超える相互作用をするペアが同定されている。)
3. ファージ提示法(ファージディスプレイ法)
この方法では,以下のものを利用する:
その方法: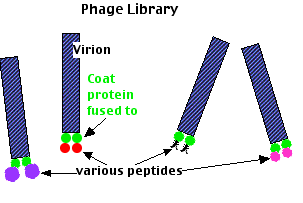
ファージ表示法はまた,モノクロナールクローン抗体を作製するのにも利用される(マウスを使わずに)。
4. タンパク質チップ
 タンパク質チップは DNA チップとほとんど同じ原理で働く。
タンパク質チップは DNA チップとほとんど同じ原理で働く。
原理は簡単であるが,タンパク質チップは DNA チップに比べると非常に困難なことが多い。その理由は,タンパク質は,
これに対して,DNA 断片はその塩基配列にのみ変化があるだけで,単純な Watson-Crick 塩基対合のルールに従って結合する
三次元構造
異なるタンパク質がお互いにどのように相互作用して,機能的な複合体を形成するのかを最も理解しやすい方法は,複合体の三次元構造を決定することである。これには 2 つの方法がある。すなわち,
X 線結晶学 にはタンパク質を結晶化する必要がある。これは,2 種類以上のタンパク質の複合体の場合には通常困難な場合が多い。
ここにタンパク質の三次元イメージの例を示す。
どちらの場合もタンパク質は DNA に結合しているが,タンパク質同士でも ( 同質二量体として ) 結合していることに注意して欲しい。
核磁気共鳴分光法 は結晶化できないタンパク質の三次元イメージを作製するのにとくに有用である。
March 04, 2020